Greetings investigators! Have you ever been 50 browser tabs deep in an investigation, only to realize that you don’t really have a good way of saving your session? You could just copy and paste each URL into a file, or save everything to a bookmarks folder and export it, but doing everything automatically is much better.
There are of course quite a few paid tools that do this, such as Hunchly and Vortimo, which are both very good. For the sake of learning however, we can build something simple that will take care of some basic tasks without the price tag, with only around 100 lines of Python code.
We’ll explain how in this blog post, but if you are impatient, then you can get the finished Python script here: Link.
It should be stated that the script we write will be for Firefox. Different browsers record session information in different ways, and the way Firefox stores its info is the easiest for us to work with. We will also be working on the Ubuntu Operating System (OS). If you use another OS for your investigative work, you may need to adjust a few lines in the script. Note that since the Tor browser is Firefox-based, this script could also work with Tor, with a few modifications.
Our plan for the script is simple: Record all sites we visit without duplicates, screenshot them, and save them to a file so we can check them out later. It is of course possible to do much more than just this, but for the purposes of this blog post, we will try to keep things simple.
Starting out, we need to know two things: Where the Firefox session information is stored, and where we should store the output of our own tool.
Firefox allows users to have different profiles that they use, and information about sessions is profile-specific. By default, Firefox comes with the ‘default’ and ‘default-release’ profiles. We can find these in /home/{username}/.mozilla/firefox, where {username} is the name of the user on the system. Note however, that each profile folder has a prefix of some random characters in front of it:

We could, of course, hardcode the path for our system, but that would mean that everyone would have to change the script to make it work for their system. Instead, we use a technique called globbing, to specify a regex pattern that the script should look for:

Globbing means that the system will check all paths in the specified directory, and return a list of options that match the pattern. The file that stores the session information is ‘recovery.jsonlz4’, but we don’t know if it’s under the ‘default-release’ profile or the ‘default’ profile. Different people might use different profiles, and we want to make sure that our script works with all possible default settings out of the box.
To that end, we use globbing to let the OS tell us where the ‘recovery.jsonlz4’ file resides. It is unlikely that someone would be using both profiles, so we can safely assume that the list we get back will have only 1 item, which will be in position zero (lists in python start at index 0).
Fortunately, figuring out where to store the output of our tool is much simpler: We will make a new directory inside the current one (i.e. the one our script was launched from), and store everything inside there. Our directory’s name will be the timestamp of when the tool was ran, so that our users can distinguish between their different sessions easily.
The rest of the code is specific to the libraries we use in our script, but it’s function is actually pretty simple.
First off, we use the playwright library to emulate the operation of a proper browser. This is important for two reasons: One, some sites don’t work properly without JavaScript, so if you tried to save them, all you’d get would be a blank page saying ‘Please activate JavaScript’. Two, because JavaScript is sometimes used to request resources for the current page. Since we want to save everything we can to a file, not running JavaScript might mean that we miss out on some dynamically loaded resources that we would otherwise have gotten.
This is the code that starts a new browser session:
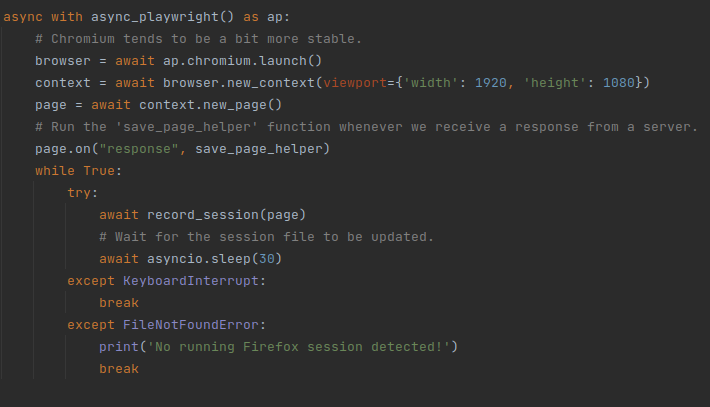
Most of the code is initializing stuff and handling exceptions. The relevant bits are the lines of code where the “save_page_helper” function is made to trigger whenever we receive responses from websites, and the infinite loop in which we run the “record_session” function.
Let’s explore the “record_session” function first. In order to record our session, we need to know what pages we visited so we can save them. That information is stored in the ‘recovery.jsonlz4’ file that we located earlier, but it is compressed. We first need to decompress it, and load the information into a variable:

We ignore the first 8 bytes – they are not part of the file’s data.
Now that we have the information in the session file, we need to extract the URLs that we visited. Each Firefox window has a list of open tabs. Each open tab has a list of URLs that we have visited. Some URLs are internal to Firefox (they begin with ‘about:’), so we can ignore them. As for the rest, we will check if we have seen them before. If we didn’t, we save the URL in the “Session.txt” file in the new directory that we created. Then, the playwright browser visits the page:
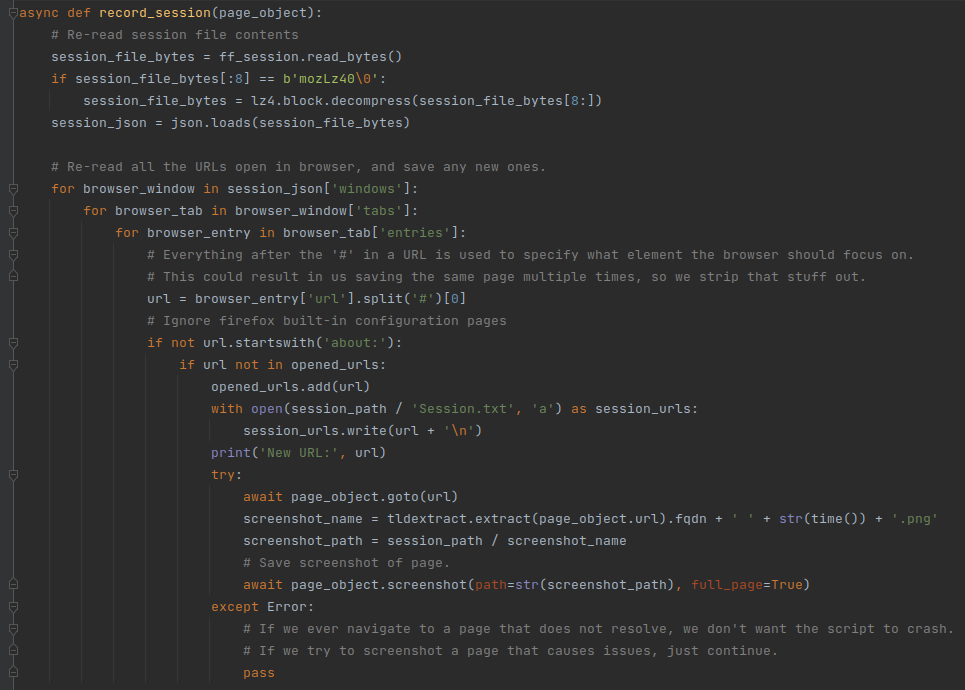
We have the playwright browser visit all the URLs, so that the “save_page_helper” function triggers and saves the pages to disk. For good measure, we also take a screenshot of the website – we’ll talk about this part of the code later.
Let’s continue by checking out what the “save_page_helper” function does. When we visit a page, we get a set of responses by the website that give our browser necessary information to display it. We have configured our browser to run a custom function whenever it receives information from a website:

The ‘save_page_helper’ function essentially just saves the response we get from the website to a file. The name of the file corresponds to the URL of the resource being saved:
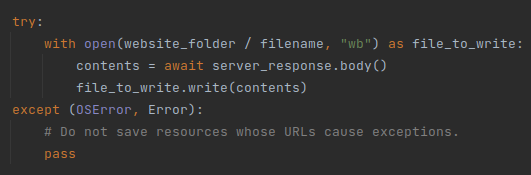
Some exceptions may occur in cases where the URL of a resource is too long to be a pathname, or if the system is running out of storage space. We make sure to handle those issues silently. In most cases, very long path names are tracking pixels with long UID codes. Normal website resources tend to have reasonable names and are going to be stored properly on the disk.
There is a caveat to this: opening a saved website won’t be the same as visiting it online – the formatting will have issues, and a lot of the resources in it will not appear. Still, the page and all the resources are stored locally. This ensures that investigators have backups of the text and pictures that were hosted on the website, in case that something happens in the future.
It is possible to save a page as a single file, with the correct formatting, in most cases. The way to do this would be altering the page’s code to include the resources as base64-encoded strings. While this is good for presentation, there are two main issues with it: One, it changes the source code of the page. This can be important if you want to have a copy of the code exactly the way it is online, for presenting as evidence for example. Two, by encoding the images as base64 strings, you miss out on extracting any potential metadata that they have.
To best of both worlds, we save the page as is, and then take a screenshot of the entire webpage:

If however you still want to save pages as files, and have them look the way they normally would, there is a tool that can help you: Webpage2html. This tool can also make adjusted copies of locally saved sites, so you can open them properly in your browser. There are also free browser extensions that can save sites as a single file locally, like SingleFile.
Lastly, there is one very important thing that we have to do, and that is to give our tool a catchy name: FireWatch. Our tool has nothing to do with the actual concept of a fire watch, but the name sounds cool, so we went with it. If you didn’t click the link to the tool in the introductory paragraphs, here it is again to save you the scrolling: Link to FireWatch.
For the purposes of this blog post, we will stop development here, though there is still some room for improvement. For starters, the cookies that a browser stores often have an impact on their browsing experience. Re-creating the cookies used by the Firefox browser should take us a step closer to replicating our browser activities.
Additionally, having some means of mapping out our path through the websites on each tab would help an investigator remember what lead they were following during their browsing session. Investigators might also need to quickly pivot from their session information – for example, scraping all URLs and contact information from a set of trafficking pages.
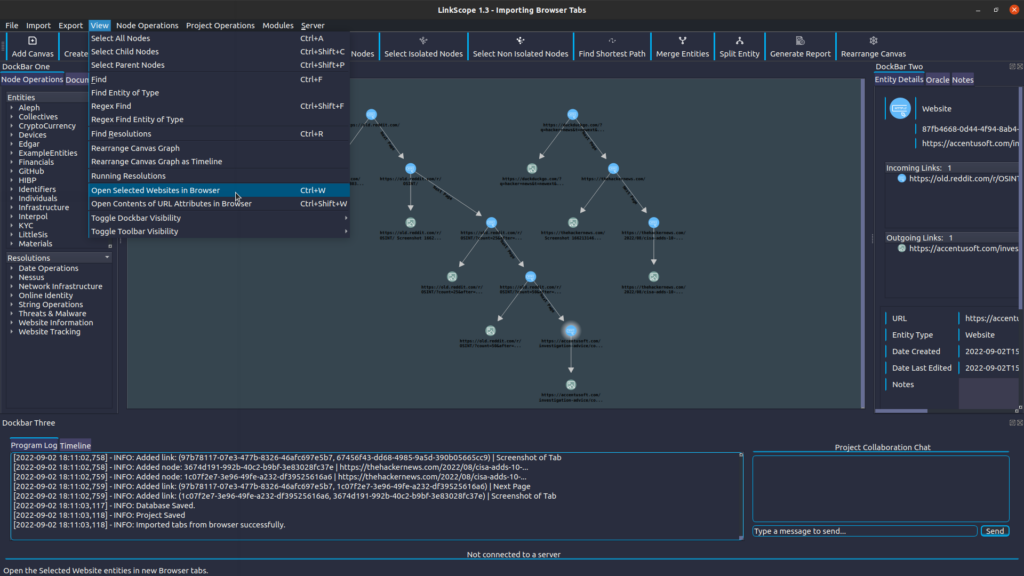
LinkScope comes equipped with the ability to seamlessly import your browser tabs as entities – no external tools needed! Import your entire session, showing what URLs were visited in each tab, and take a timestamped screenshot of every page:
Then, pick up where you left off, by selecting the websites you are interested in and opening them in your browser:
The browser is the primary way of exploring the the world’s largest data set, the Internet. Making sure that your workflow includes tools that streamline your interaction with it makes your investigations faster, and more effective.
We hope that you’ve enjoyed this brief dive into Python scripting, and that you’ve found our blog post helpful!
Best Wishes,
AccentuSoft